When LLMs Flip Coins, Is the Probability 50%?
If we ask AI to flip a coin, is the probability of heads 50%? If we ask it to “randomly” say a number from 0 to 9, is it really random? What about asking it to pick a color?
But before the article starts, let’s play one round of rock-paper-scissors. Now, by intuition, decide what you will play this time: rock, scissors, or paper? At the end of the article I will tell you what I played.
At lunch today I was browsing Bilibili and saw a video from MediaStorm: 《在 AI 里抛硬币,概率是 50% 吗?》. The question is simple: when flipping a coin, heads is about 50%. Then if we let AI flip coins again and again, is the probability of heads still 50%? Tim’s method was to let a video world model generate a large number of “coin flipping” videos, then manually count the ratio of heads.
But as someone who often deals with LLMs, I realized this question may be much more interesting than imagined. This article uses text large models as examples. First, we start from the “output” of LLMs. When you ask it “flip a coin, is this coin heads or tails”, the large model is not really flipping a coin in the background, and behind it is also not 50% randomness. Instead, it is “deterministic”.
Many people think large models are random things. In our daily use, for the same question, it answers differently each time.
Actually not. The large model itself is a pure deterministic function: given a piece of text, it gives a score to each of the more than one hundred thousand candidate tokens in the vocabulary. This score is called a logit. A higher score means “it wants to say this more”. With the same input, this group of scores is always exactly the same, with no randomness at all.
This probability is then converted into a concrete token by a module called sampling. The sampling module may work like this: “sort probabilities from large to small, and randomly choose among the top 10”. This is the source of LLM randomness. But in the original output, that is, in the vocabulary probabilities, are the probabilities of “heads” and “tails” really the same? Or do different models have their own preferences? The experiment results are very interesting.
So I use Qwen3 4B and Qwen3.5 4B as examples, directly look at their logits, and observe the inner monologue at the moment the model opens its mouth. It covers Chinese, English, Japanese, different ways of asking, rolling dice, and choosing colors.
Coin Flip Experiment: Is It Really 50%?
Let the two models flip coins, changing three languages and three ways of asking. Note: each language uses its own “heads/tails” words: Chinese 正/反, English heads/tails, Japanese 表/裏. These six words are all exactly one complete unit that cannot be split further in the eyes of the two models, so comparison is fair.
Three ways of asking (each row in the figure is one kind. Using Chinese as the example, it corresponds to the row label Chinese · ...):
options 正,反: list options in the prompt, with heads first: “Please flip a fair coin. Answer only one character: 正 or 反.”options 反,正: also list options, but tails first: ”… Answer only one character: 反 or 正.” This is just to see whether order has an effect.no options: do not give any options, and ask naturally: “Flip a fair coin. Which side lands? Answer only one character.”
The left column is Qwen3 4B, the right column is Qwen3.5 4B. Each column shows how much probability the model most wants to output “heads” or “tails” respectively, aggregated among heads and tails.
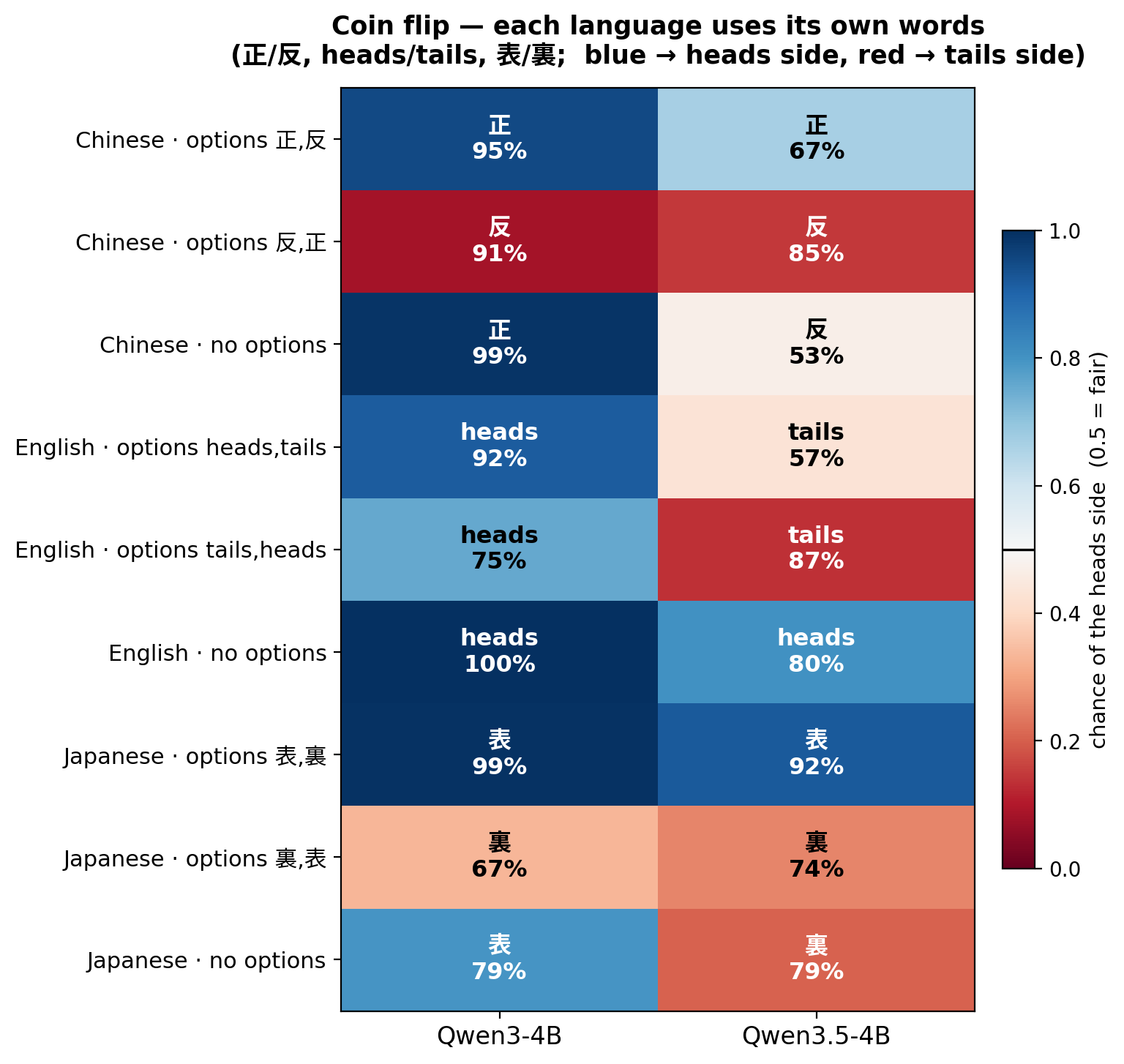
The model is repeating the first option that appears. If you say heads first, it has a high probability of answering heads. If you say tails first, it has a high probability of answering tails. If you do not say it, Qwen3 4B has a very strong “heads complex”. Across three languages, it is more biased toward the “heads” side: Chinese 正 99%, English heads 100%, Japanese 表 79%. “正/heads/表” is the default answer in its mind.
Qwen3.5 4B under natural Chinese questioning: 正 47% / 反 53%, is the fairest time. When changed to English and Japanese, it is also compromised toward heads.
Add another interesting experiment. Every coin flip is an independent event, which means every coin flip has 50% probability. But if we tell the model this is the k+1-th coin flip, and the previous k times were all heads, what will it output?
Continuously flip a fair coin, and record each result in order (heads recorded as “正”, tails recorded as “反”): 正 正 正 正 正 正 正 正 正
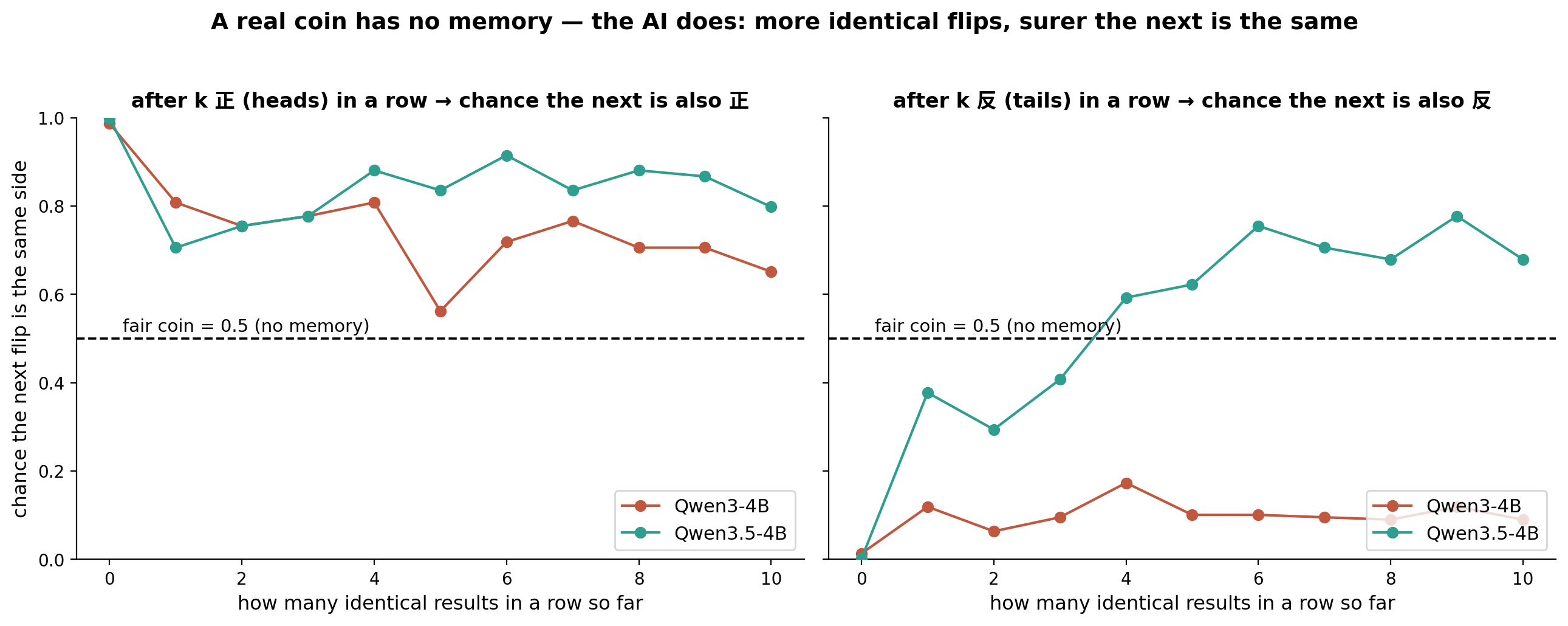
Qwen3.5 is very interesting. If the previous results are heads, it believes with high probability that the later result will also be heads, like a gambler. If tails came first, when k is small, it may still hesitate: last time was tails, maybe the next time will be heads. As tails increase, it will also tend toward tails.
And Qwen3 4B continues the previous style: it just likes “heads”.
Rolling Dice: Among 1-6, Who Does the Model Prefer?
A coin has only two sides, heads and tails. A 50% probability feels not interesting enough. We let the model roll a die once.
Ascending option list: Please roll a fair six-sided die. Output only one token: 1, 2, 3, 4, 5, or 6. Descending option list: Please roll a fair six-sided die. Output only one token: 6, 5, 4, 3, 2, or 1. No options: Roll a fair six-sided die. What is the point number? Answer only one digit.
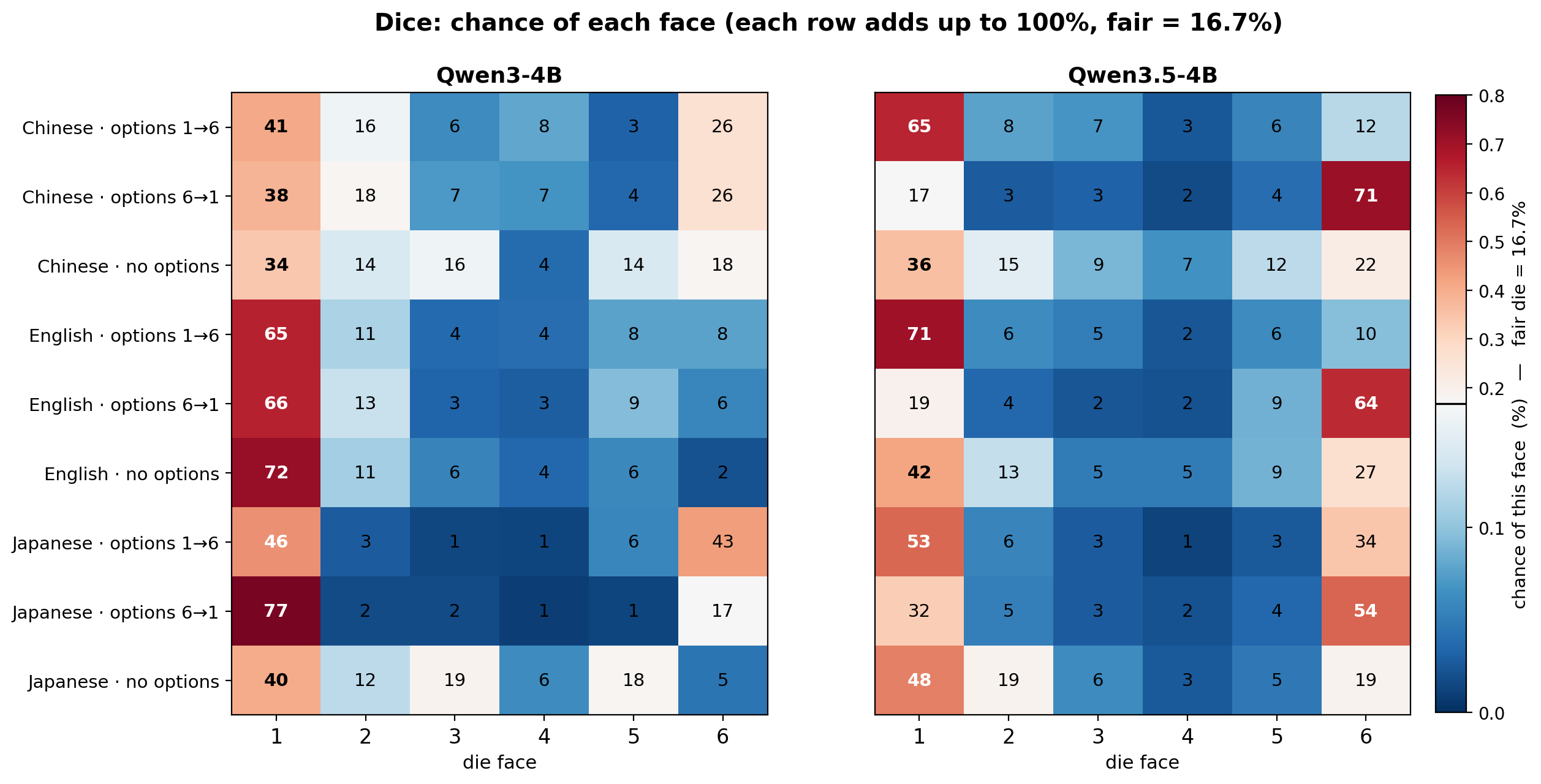
The conclusion is not quite the same as the coin. If asking in Chinese, it is indeed consistent with the coin conclusion: say 1 first and it is 1, say 6 first and it is 6. For Qwen3.5 4B it is like this. But for Qwen3 4B, if asking in English and Japanese, it tends more toward 1.
If no options are given, both are more inclined to output 1, then 6, while 3, 4, and 5 are like they never existed.
Random, Random, or Random
I do not know if anyone has watched a street interview where the host asks: “Randomly say an integer between 0 and 9, output only this number.” Guess what number people prefer? Friends who want to know the answer can search it themselves, haha.
Including many challenges. We also let LLMs play it.
Random digit: Randomly say an integer between 0 and 9, output only this digit. One of four: Randomly choose one from options A, B, C, and D, output only one letter. Random color: Randomly say a color, output only one character: red, yellow, blue, green, black, or white. Rock-paper-scissors: Let’s play rock-paper-scissors. You go first. Output only one character: rock, scissors, or paper.
First look at the digit experiment.
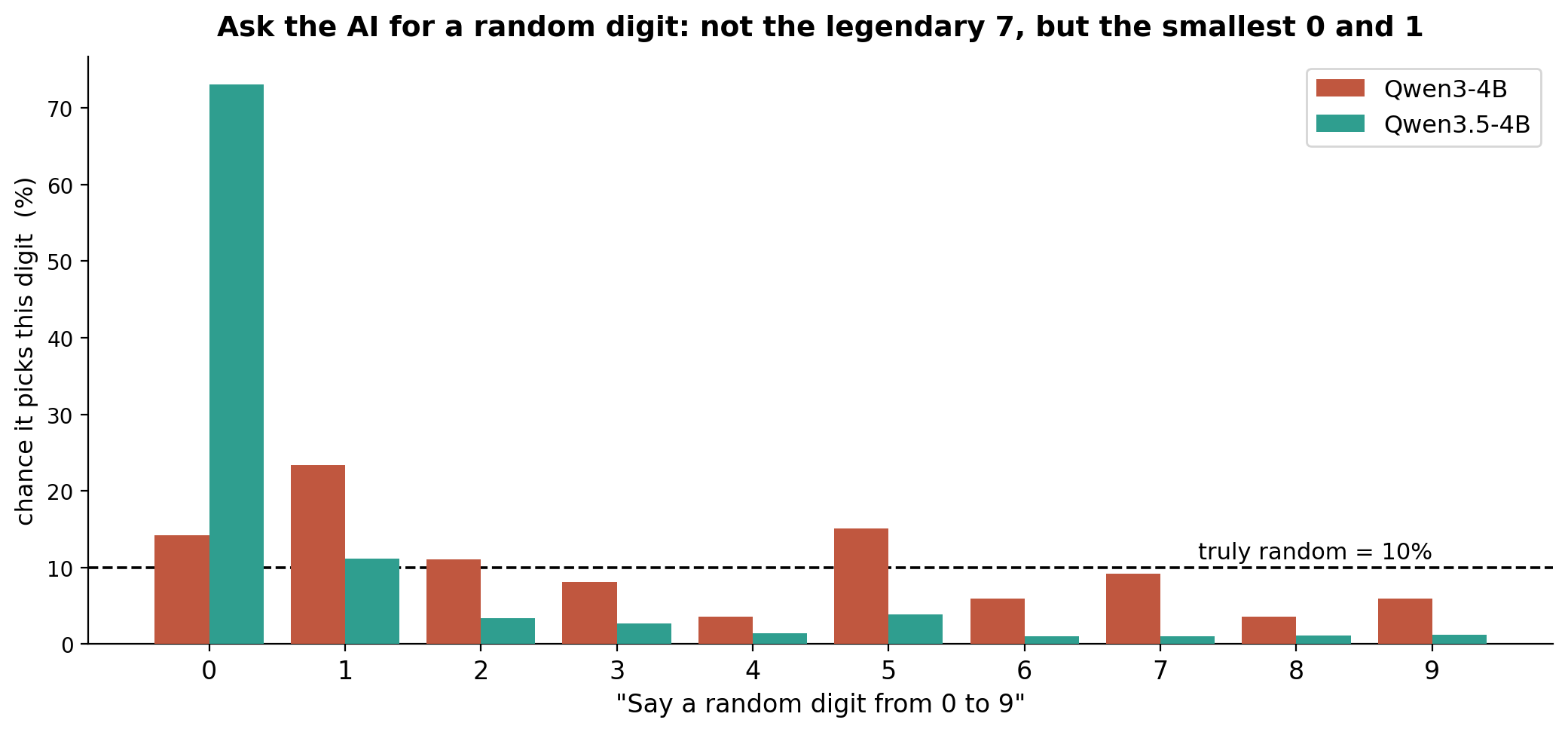
Qwen3 4B is relatively even, but prefers 1 more, while Qwen3.5 4B is very fond of 0.
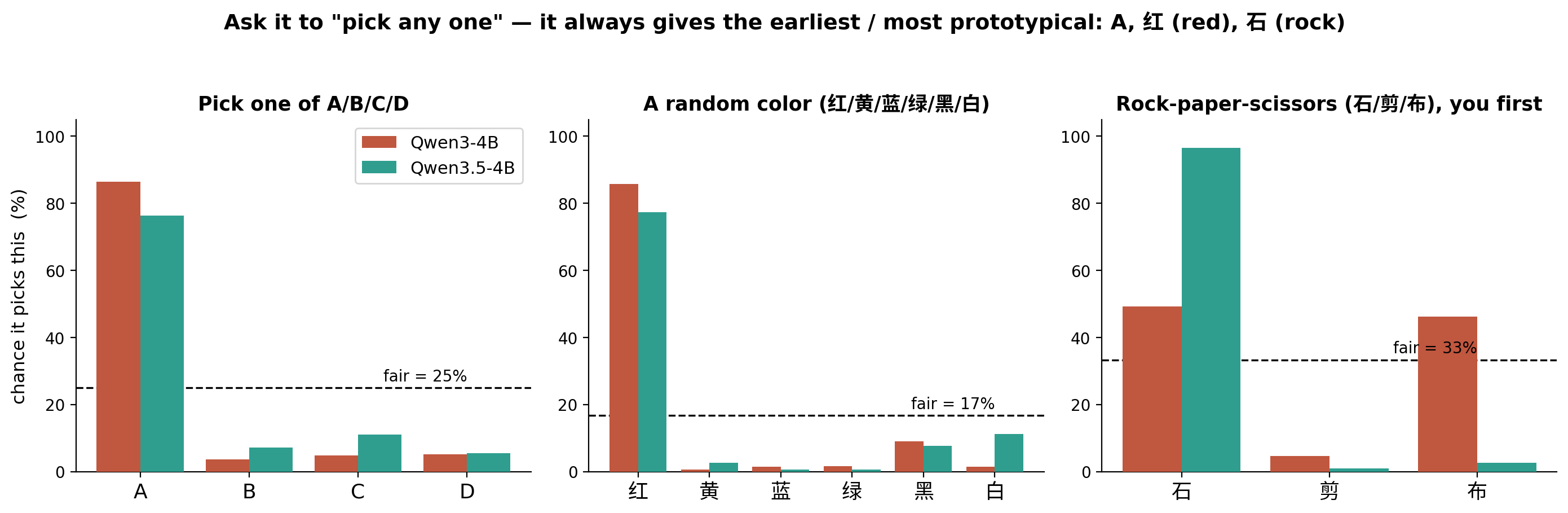
For ABCD, it likes A more, then C.
For colors, it likes red more, then black and white.
For rock-paper-scissors, it likes to play rock more, then paper, and does not play scissors much.
At this point, you can confirm your option again. The truth will be seen at the end.
It seems always biased toward the option we gave first, or the smallest and most typical one. From training, AI is a machine that “finds the maximum-probability answer”, so the option itself in the language world, and the distribution in the corpus, may already decide this tendency. It is like asking someone for directions at a fork in the road. He is more inclined toward that wide road, the good road.
Who Made the Decision, and How Was the Decision Made?
Since we can get logits, we can also go one step further into the inner world of the model. A model is made of layers, one layer after another, like a telephone game: “Hey, this person wants us to output heads or tails”, “oh, output a heads or tails”, “how about heads”… “output heads”. After passing through several people, the model finally makes the decision. So we want to see at which layer it has already made the decision. For example, why is Qwen3 4B so biased toward “heads”?
So this experiment is like this: if after some layer, I directly look at what state its logits are in.

From left to right are the model layers, from shallow to deep. The darker the cell color, the larger the probability of the two words “heads/tails”. The left side of each row is basically white, and it only starts preparing to output when it is close to the end. This also implies that you cannot “quantize layer”. The model does not know the answer from the start, but makes the decision in the few layers close to the exit.
At the same time, according to attention, we can also calculate an attention score, to see how attention is thinking about this question after we ask the question. Since Qwen3.5 is a hybrid model, we only took its full-attention layers.
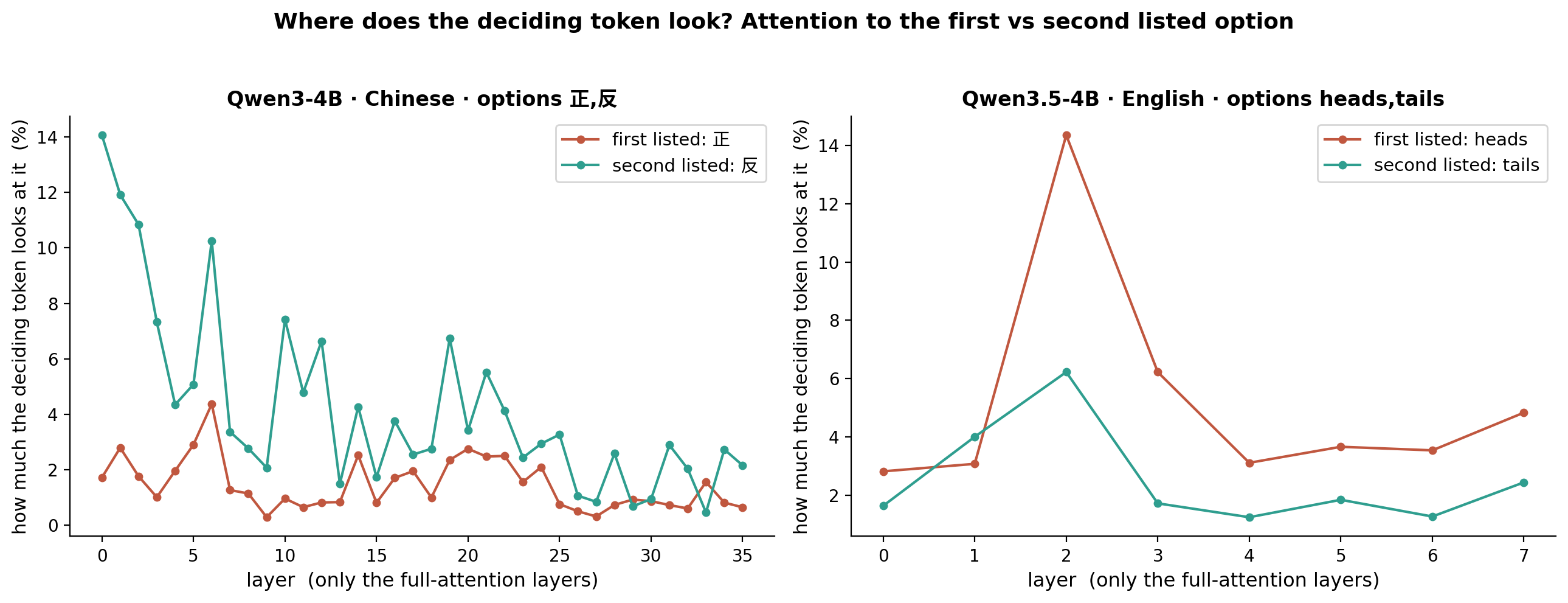
In the coin flip experiment of “heads then tails”, Qwen3 instead pays more attention to “tails”, but likes “heads”, while Qwen3.5 4B keeps its attention on heads.
So this leads to another more interesting experiment. When the model computes attention, we directly cover the two options with a mask. This option is generally used to handle padding, but we can also use it here for experiments. What effect does covering heads and tails have?
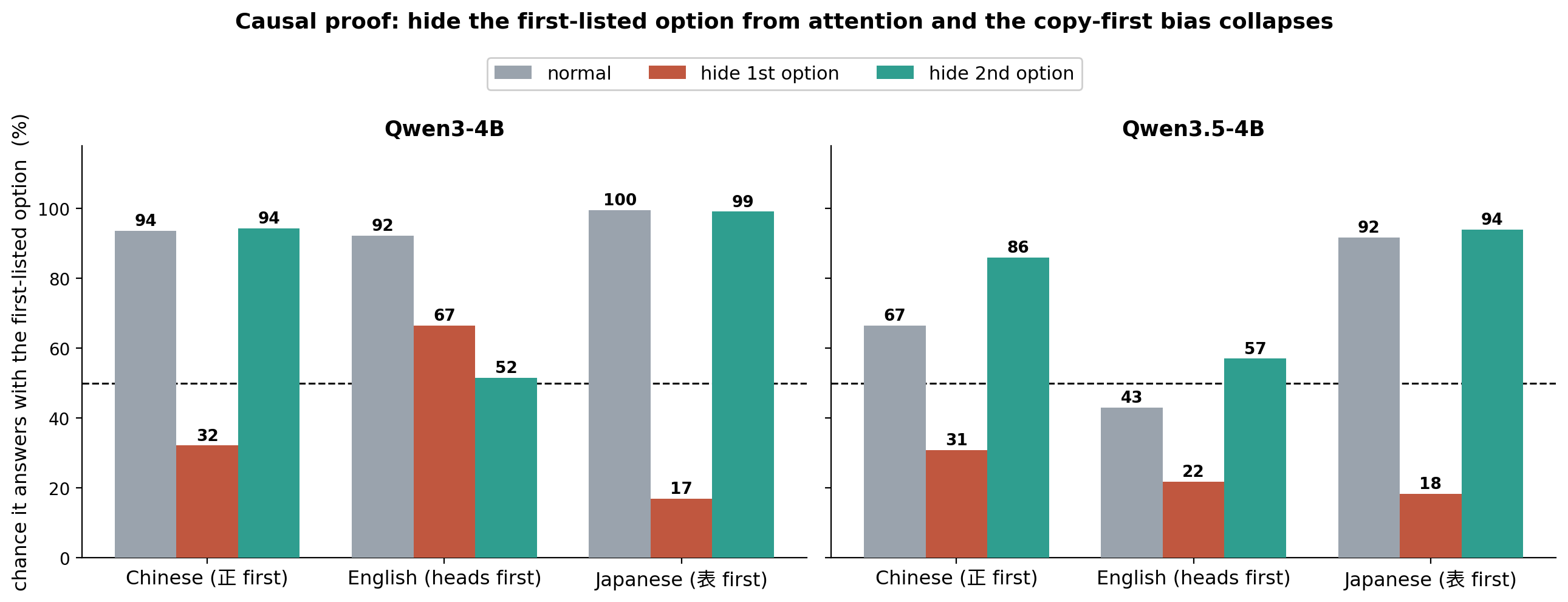
Covering the first option will quickly reduce the probability that the model follows and chooses the given option. It no longer chooses to repeat. Covering the second option does not have much effect. So sometimes attention score cannot represent any actual meaning. This may involve some KV cache sparsification work.
I chose rock!
If possible, you can tell me in the comments what you just played: rock, scissors, or paper. Let’s see the logits distribution of humans facing rock-paper-scissors.